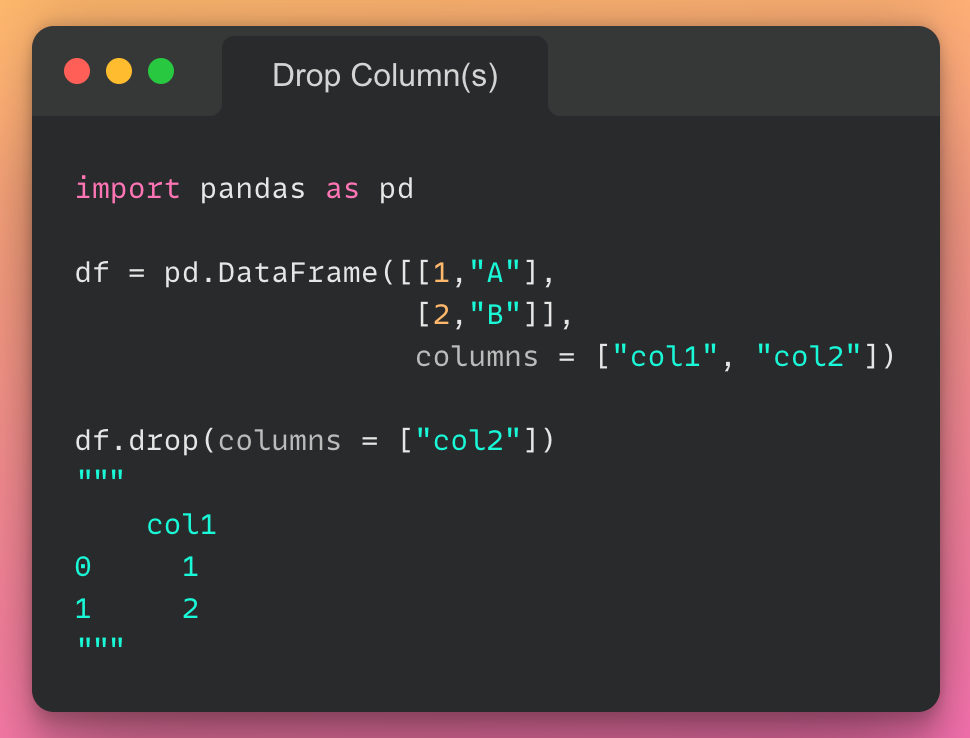
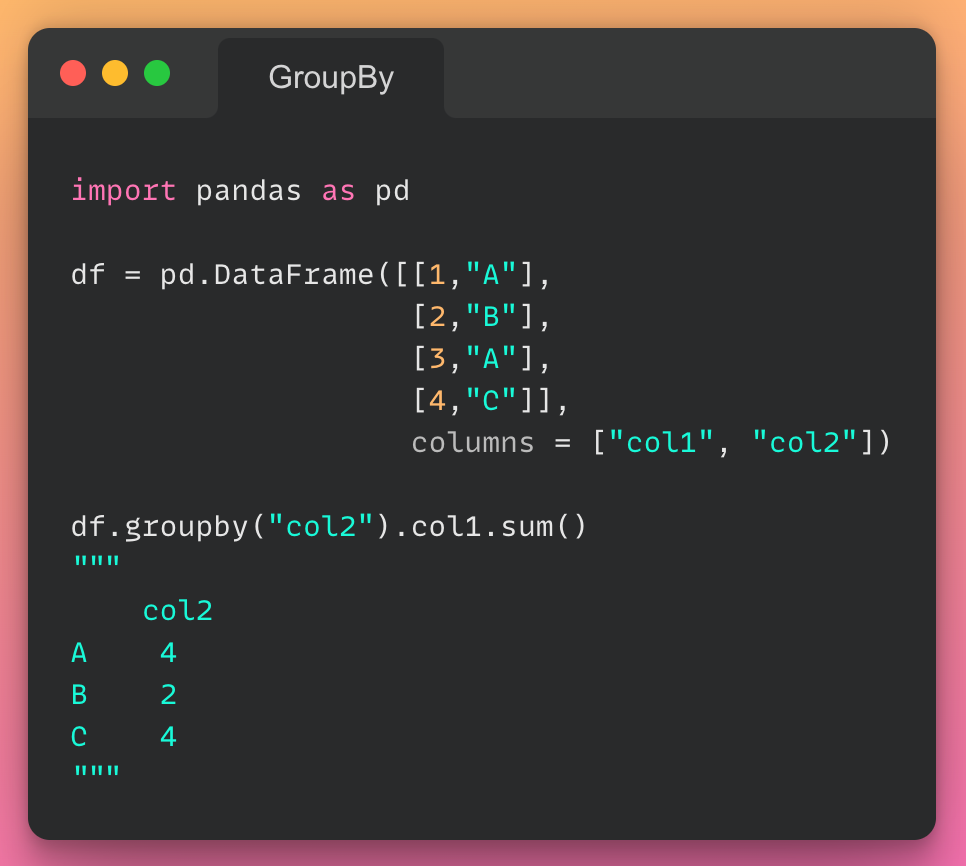
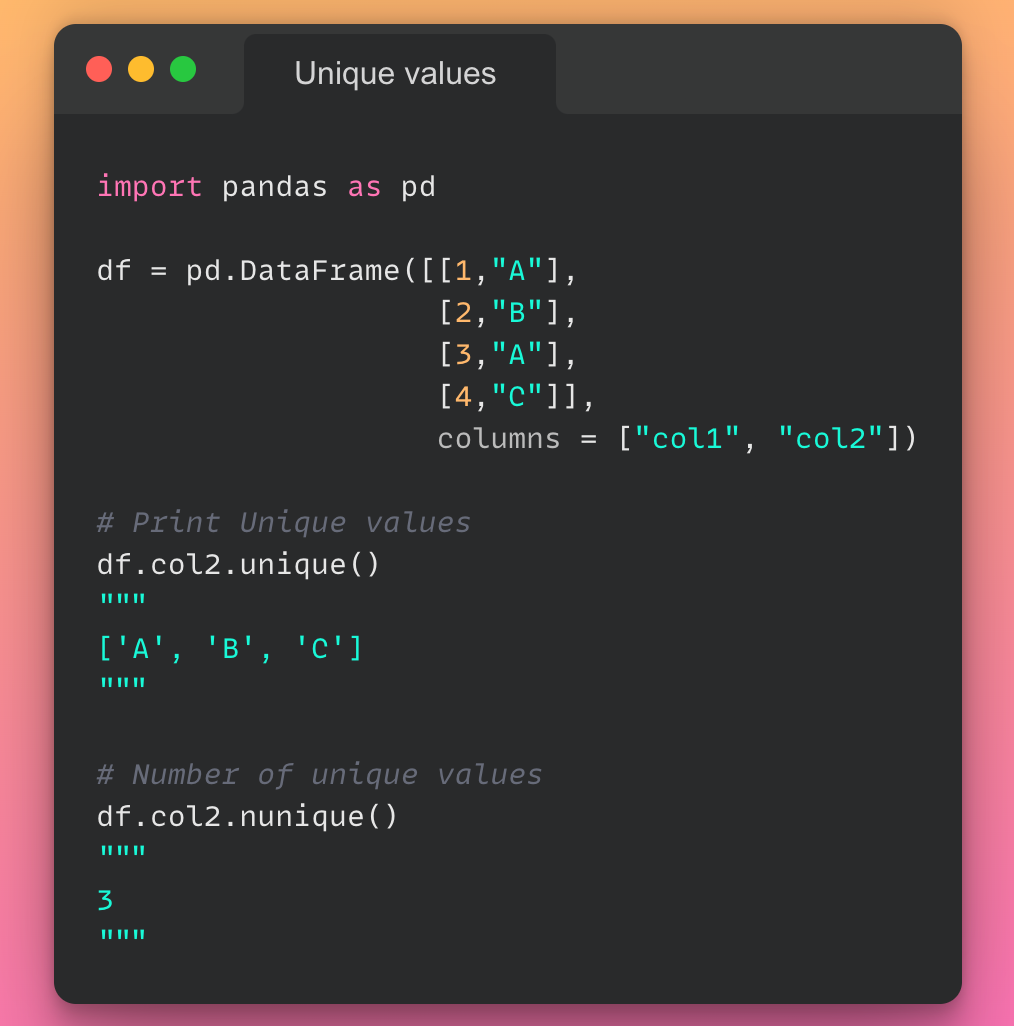
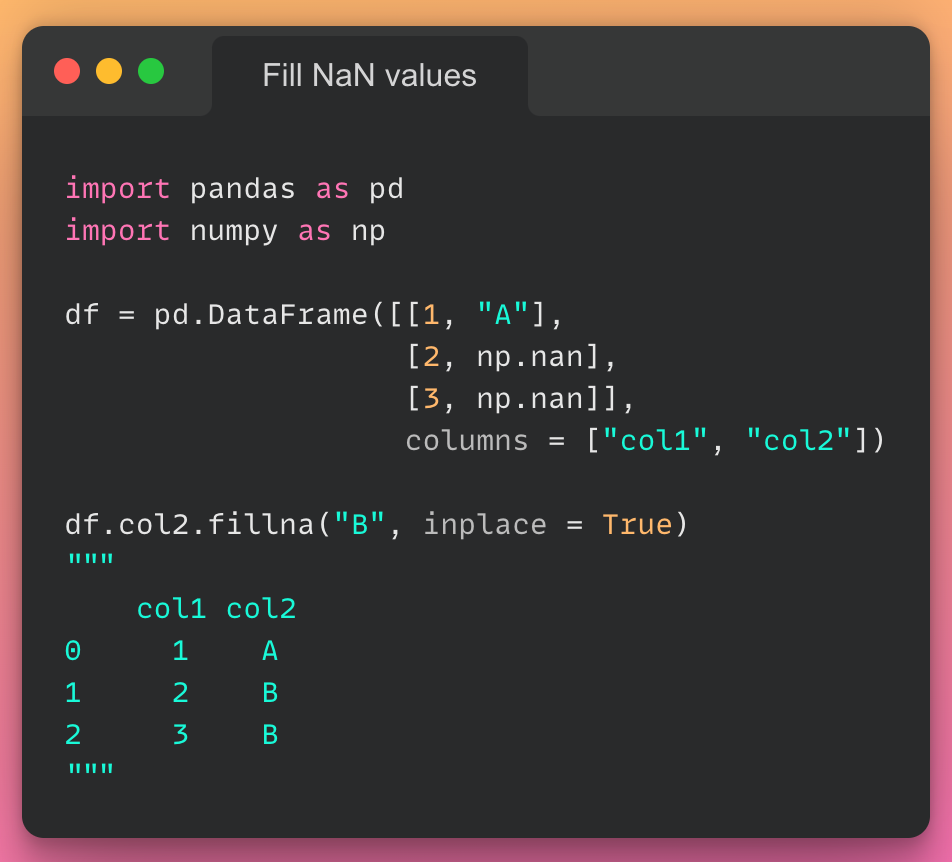
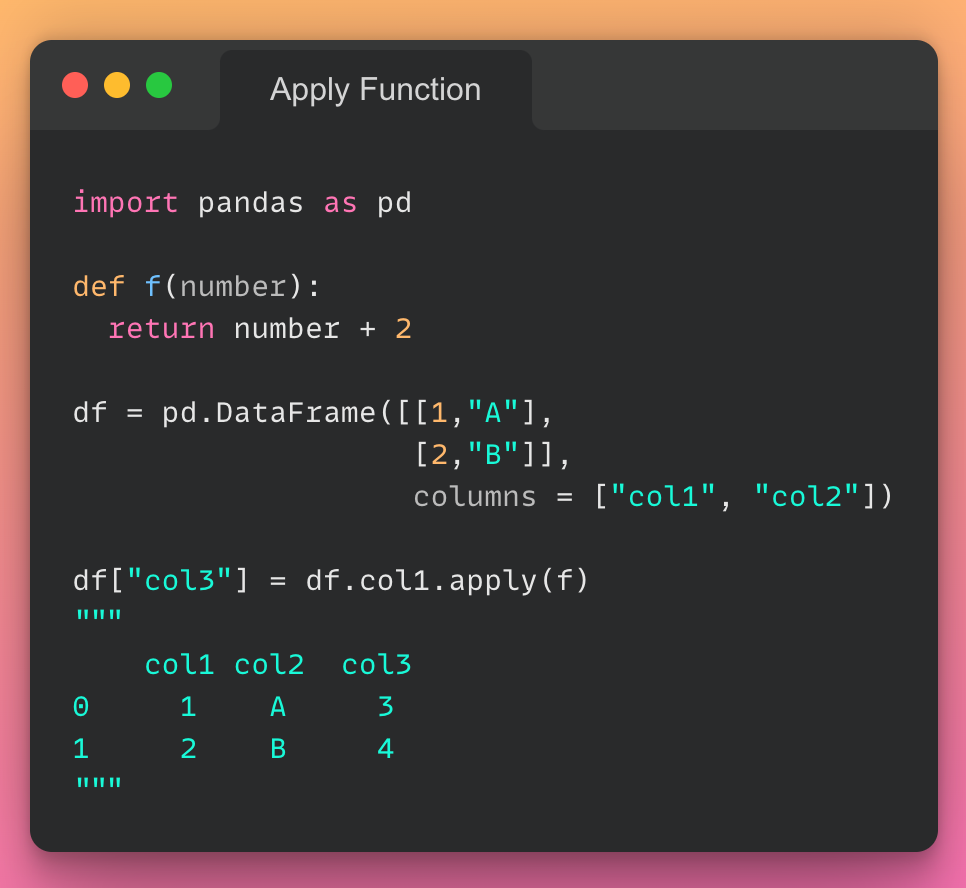
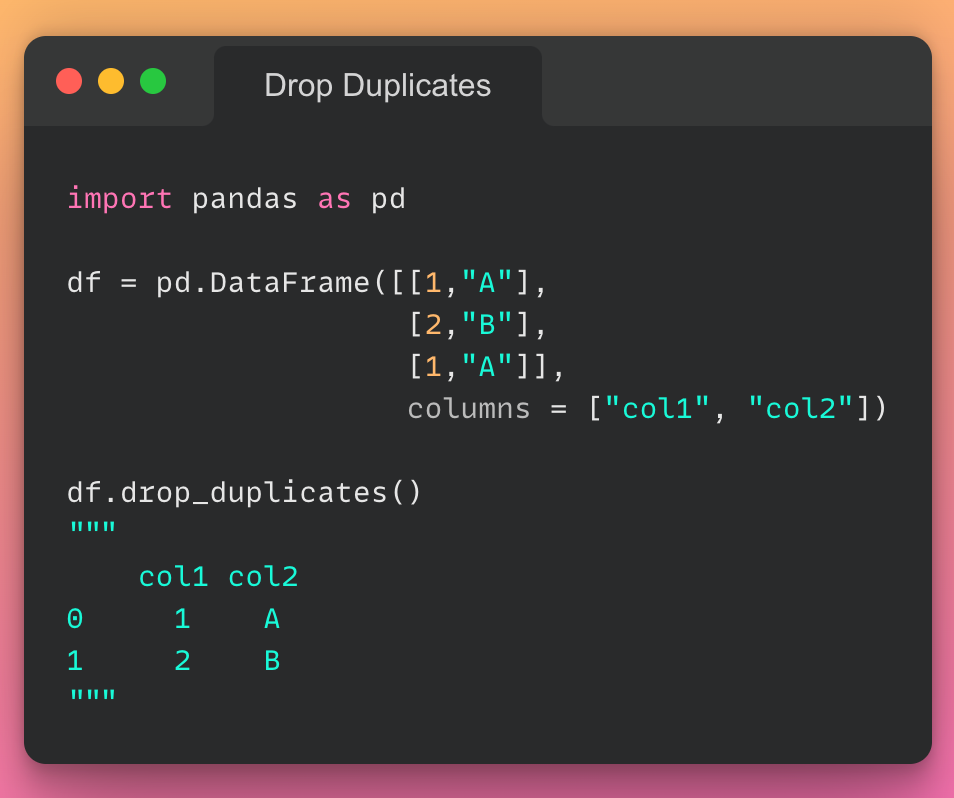
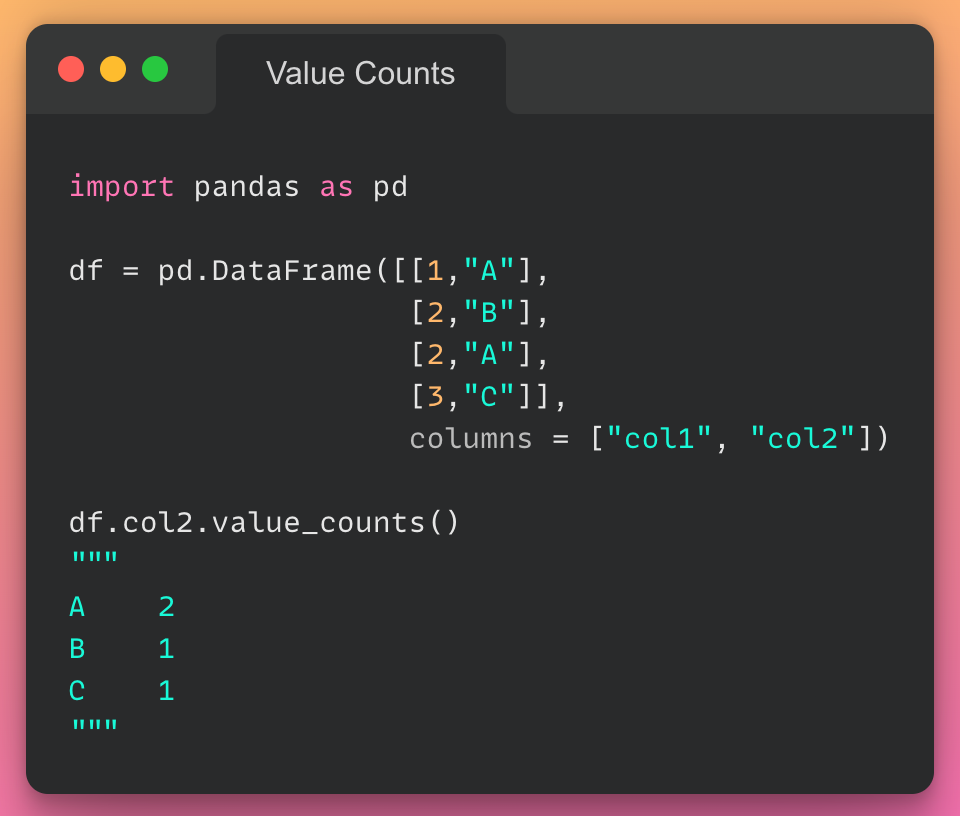
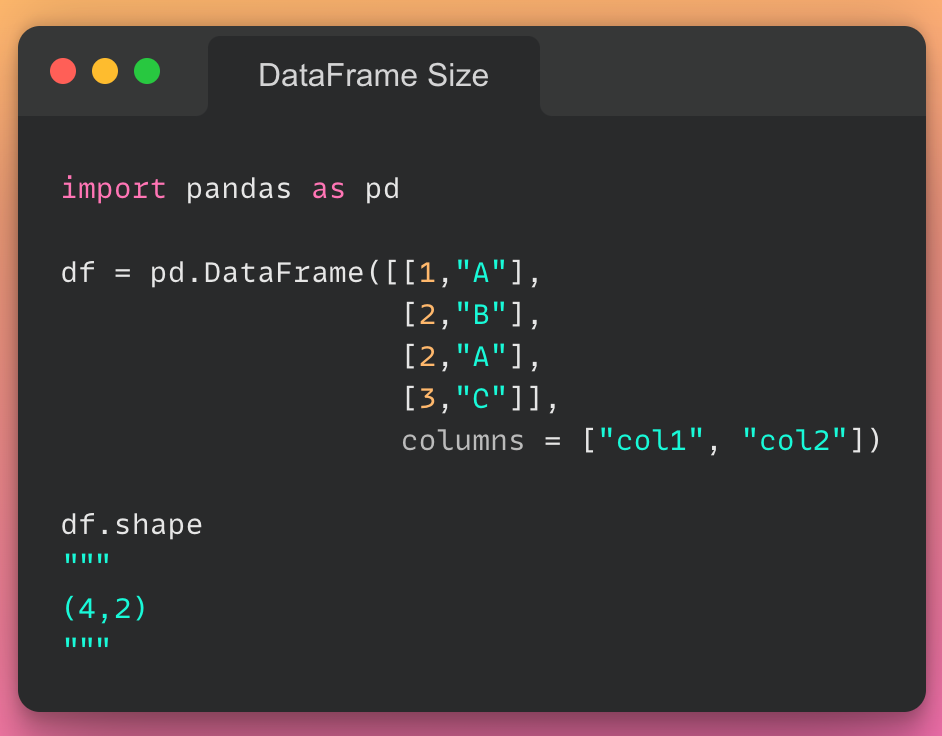
این مقاله، نخستین بار در وبسایت آذرآنلاین منتشر شده است. هدف از بازنشر آن، به اشتراکگذاری این مقالهی ارزشمند، با خوانندگان مجموعه میباشد! سپاس از تیم تولید محتوا در مجموعهی آذرآنلاین.
مقدمه
حتی اگر تا کنون در زمینهی برنامهنویسی تجربهای نداشتهاید، اما حتماً نام پایتون به گوشتان خورده است! اما پایتون چیست و چه کاربردی دارد؟ در این مقاله در این خصوص خواهید فهمید.
زبانهای برنامهنویسی از سالها قبل برای ایجاد ارتباط آسان بین انسان و ماشین به وجود آمدند. در زبانهای برنامهنویسی اولیه از یک سری قواعد و دستورات ساده برای پردازش و نمایش نتایج در یک ماشین مانند کامپیوتر استفاده میشد.
امروزه زبانهای برنامهنویسی تقریباً در هر زمینه صنعتی و تجاری که وابسته به کامپیوتر و اینترنت است، مورد استفاده قرار میگیرد. زبانهای برنامهنویسی نسل جدید از ساختار نحوی سادهتری برخوردار هستند و کار برنامهنویسی را برای کاربران سادهتر کرده است.
یکی از این زبانهای برنامهنویسی که ساختاری نسبتاً ساده دارد و در بسیاری از حوزهها قابل استفاده است، پایتون نام دارد. اگر بخواهیم به طور خلاصه بگوییم پایتون چیست و چه کاربردی دارد، میتوان گفت پایتون جزو زبانهای سطح بالا محسوب میشود، یعنی هم ساختار محور و هم شیء محور است.
این زبان اولین بار در دهه 1980 پایهریزی شد و در سال 1991 به عنوان زبان رسمی با نام پایتون معرفی گردید. تا کنون نسخههای مختلفی از این زبان منتشر شده است که جدیدترین آن در سال 2020 تحت عنوان پایتون نسخه 2.7.18 منتشر شد.
پایتون در سال 2022 محبوبترین زبان برنامهنویسی انتخاب شد که دلیل این محبوبیت، ساختار ساده و کاربردهای فراوان آن است. در این مقاله قصد داریم در مورد این زبان برنامهنویسی، موارد استفاده از آن، مزایا و معایب بهکارگیری پایتون و سایر ویژگیهای آن صحبت کنیم.
پایتون چیست؟
پایتون یک زبان برنامهنویسی است که بیشترین تطبیقپذیری را در بین سایر زبانهای برنامهنویسی مشابه خود از جمله Ruby و Swift دارد. منظور از تطبیقپذیری یعنی قابلیت استفاده در پلتفرمهای مختلف و برای اجرای کدهای گوناگون است.
پایتون در حقیقت یک زبان برنامهنویسی چندمنظوره است و تقریباً در هر جایی که از دادهها، محاسبات ریاضی یا خطوط کد استفاده میشود، قابل استفاده است. به عنوان مثال، پایتون برخلاف جاوا محدود به استفاده برای توسعه صفحات وب نیست.
مانند بسیاری از زبانهای برنامهنویسی، پایتون به صورت پشت سر هم با یک مفسر به کار میرود که خطوط نهایی کدها را اجرا میکند. منابع رایگان زیادی برای یادگیری زبان برنامهنویسی پایتون وجود دارد که با توجه به ساختار نحو انگلیسی آن، یکی از کم دردسرترین و سادهترین زبانهای برنامهنویسی از نظر یادگیری و خواندن است.
پایتون سه دهه پیش ظهور کرد. مخترع آن، برنامهنویس هلندی، Guido van Rossum بود که نام آن را بر اساس نام گروه کمدی مورد علاقه خود در آن زمان، یعنی Monty Python’s Flying Circus، نامگذاری کرد. از آن به بعد، این زبان محبوب به همین نام معروف شد.
پایتون به دلیل قدرتمند بودن، سریع بودن و سرگرمکنندهتر کردن برنامهنویسی معروف است. کدگذاران پایتون میتوانند متغیرها را به صورت پویا تایپ کنند بدون اینکه نیازی به توضیح هر متغیر داشته باشند.
کاربران میتوانند پایتون را بدون هیچ هزینهای دانلود کرده و بلافاصله شروع به یادگیری کد نویسی با آن کنند. کد منبع این زبان به صورت رایگان در دسترس بوده و برای اصلاح و استفاده مجدد در دسترس است.
محبوبیت پایتون به دلیل ساختار نحوی ساده و خوانایی آن است. Python که اغلب در تجزیهوتحلیل دادهها، یادگیری ماشینی (ML) و توسعه وب استفاده میشود، کدهایی را استفاده میکند که خواندن، درک و یادگیریشان دردسر ندارد. برنامههای توسعه یافته با کد پایتون معمولاً کوچکتر از نرمافزارهای ساخته شده با زبانهای برنامهنویسی مانند جاوا هستند، این یعنی برنامهنویسان معمولاً باید کد کمتری تایپ کنند.
نظرسنجی انجام شده توسط شرکت تحلیلگر صنعتی RedMonk نشان داده است که این زبان دومین زبان برنامهنویسی محبوب در میان توسعهدهندگان در سال 2021 میباشد.
موارد استفاده از پایتون کدام است؟
پایتون معمولاً برای توسعه وبسایتها و نرمافزارها، اتوماسیون، تجزیهوتحلیل دادهها و غیره استفاده میشود. از آنجایی که یادگیری این زبان نسبتاً آسان است، پایتون توسط بسیاری از افراد غیر از برنامهنویسان مانند حسابداران و محققان برای انواع کارهای روزمره مانند سازماندهی امور مالی مورد استفاده قرار گرفته است.
با پایتون چه کارهایی میتوانید انجام دهید؟ برخی موارد عبارتاند از:
- تجزیهوتحلیل دادهها و یادگیری ماشین
- توسعه وب
- اتوماسیون یا اسکریپت نویسی
- تست نرمافزار و نمونهسازی
- کارهای روزمره
در ادامه نگاهی دقیقتر به برخی از این روشهای رایج استفاده از پایتون خواهیم داشت.
تجزیهوتحلیل دادهها و یادگیری ماشینی
پایتون به یک عنصر اصلی در علم داده تبدیل شده است و به تحلیلگران داده و دیگر متخصصان این امکان را میدهد تا از این زبان برای انجام محاسبات آماری پیچیده، پردازش دادهها، ساخت الگوریتمهای یادگیری ماشینی، دستکاری و تجزیهوتحلیل دادهها و غیره استفاده کنند.
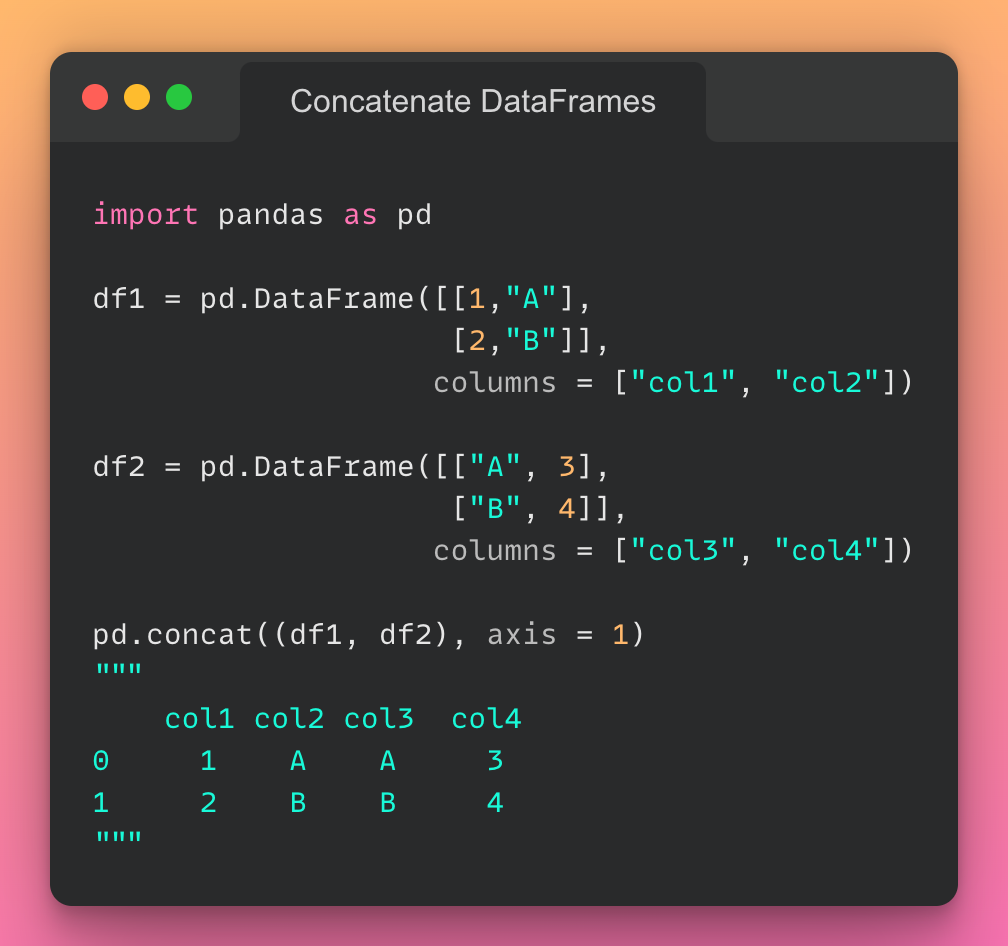
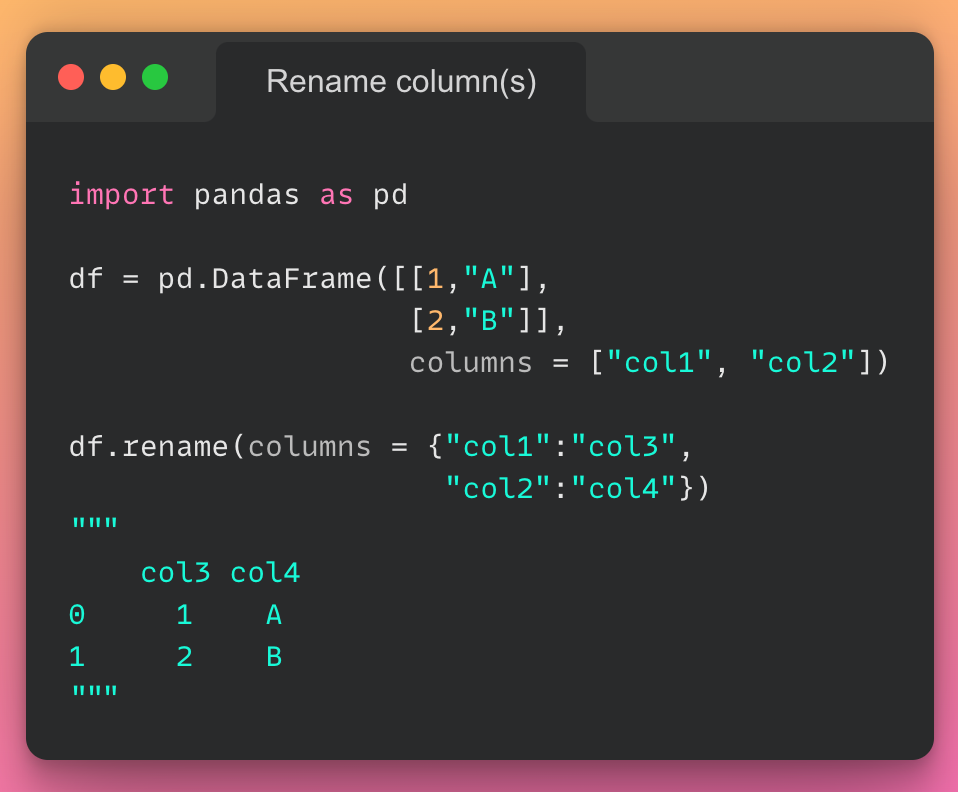
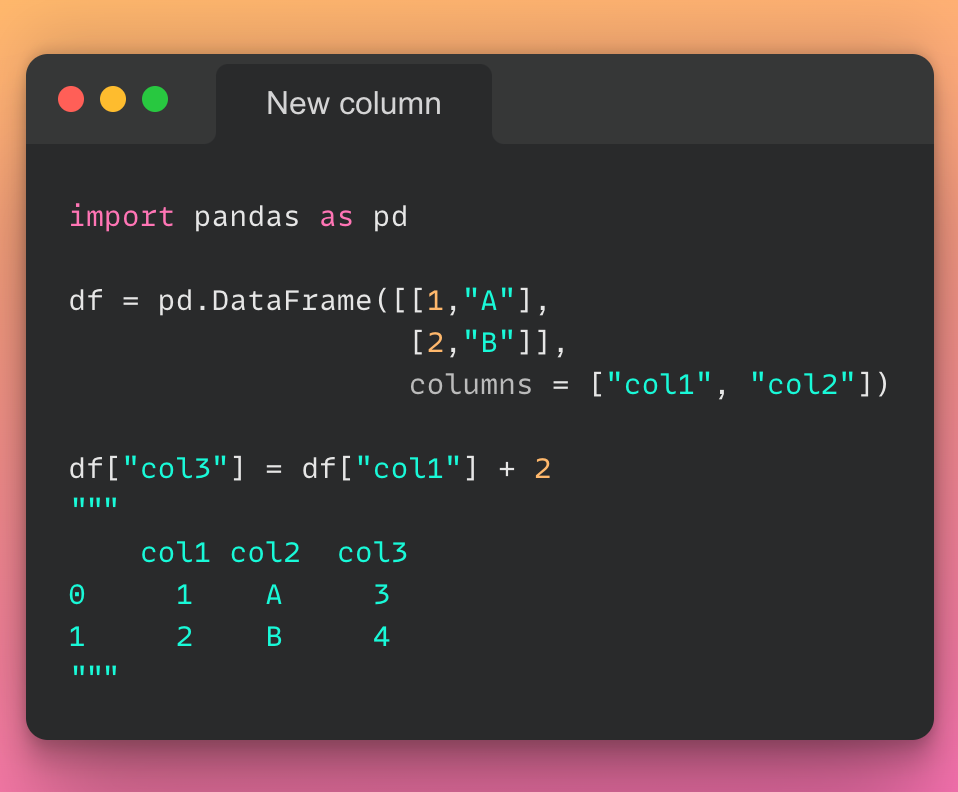
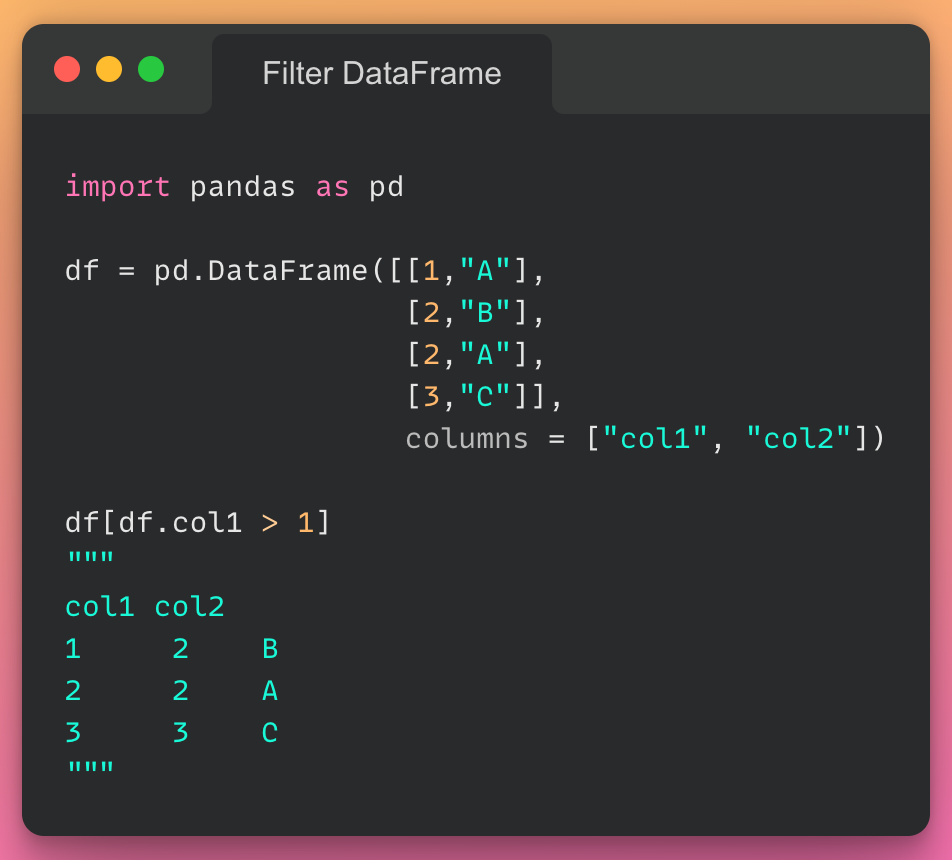
توضیح عکس: به کمک پایتون میتوان پردازش دادهها را به صورت تصویری انجام داد.
پایتون میتواند طیف وسیعی از روشهای پردازش تصویری دادههای مختلف، مانند نمودارهای خطی و میلهای، نمودارهای دایرهای، هیستوگرامها و نمودارهای سهبعدی را اجرا کند. پایتون همچنین تعدادی کتابخانه دارد که به کد نویسها این امکان را میدهد برنامههایی را برای تجزیهوتحلیل دادهها و یادگیری ماشینی به صورت سریعتر و کارآمدتر بنویسند، مانند TensorFlow و Keras.
توسعهی وب
Python اغلب برای توسعهی زیربنای یک وبسایت یا اپلیکیشن استفاده میشود. نقش پایتون در توسعه وب میتواند شامل ارسال دادهها به سرور و یا ارسال از سرورها به سیستم باشد، یا پردازش دادهها و برقراری ارتباط با پایگاههای داده، مسیریابی URL و تضمین امنیت پایگاه داده که توسط ابزارهایی صورت میگیرد که بر پایه پایتون نوشته میشوند.
پایتون چندین فریمورک برای توسعه وب ارائه میدهد. دو مورد از مرسومترین فریمورکهای پایتون عبارتاند از جنگو و فلاسک. همچنین برخی از مشاغل توسعه وب که از Python استفاده میکنند عبارتاند از مهندسان back end، مهندسان full stack، توسعهدهندگان Python، مهندسان نرمافزار و مهندسین DevOps.
اتوماسیون و اسکریپت نویسی
اگر میخواهید یک عملیات را به صورت تکراری و طی دورههای متوالی انجام دهید، میتوانید به کمک ابزارهای پایتون آن را به صورت اتوماسیون درآورید. به نوشتن کدی که برای ساخت این فرآیندهای اتوماسیون استفاده میشود، اسکریپت نویسی میگویند.
در دنیای کد نویسی، اتوماسیون میتواند برای بررسی خطاها در چندین فایل، تبدیل فایلها، اجرای ریاضی دستورات و حذف موارد تکراری در دادهها استفاده شود. حتی بسیاری از کاربران مبتدی هم میتوانند اتوماسیون را در زندگی روزمره خود به کمک پایتون پیادهسازی کنند.
برخی از این عملیات ساده عبارتاند از تغییر نام فایلها، یافتن و یا دانلود محتوای آنلاین و یا ارسال ایمیل متنی در فواصل زمانی دلخواه به خصوص برای اهدافی مانند بازاریابی ایمیلی.
تست نرمافزار و نمونهسازی
در روند توسعه نرمافزار، پایتون میتواند در بخشهایی مانند کنترل ساخت، ردیابی باگها و خطاها و آزمایش نرمافزار کمککننده باشد. توسعهدهندگان نرمافزار به کمک این زبان برنامهنویسی میتوانند تست محصولات یا ویژگیهای جدید را به طور خودکار انجام دهند. برخی از ابزارهای پایتون که برای تست نرمافزار استفاده میشوند عبارتاند از Green و Requestium.
کارهای روزمره
پایتون فقط برای برنامهنویسان و متخصصان داده نیست. یادگیری پایتون میتواند فرصتهای جدیدی را برای کاربران حرفهای در حوزههای دیگر، مانند روزنامهنگاران، صاحبان مشاغل کوچک یا بازاریابان رسانههای اجتماعی باز کند. در اینجا به صورت خلاصه برخی از کارهایی را که میتوان به کمک پایتون انجام داد و یا به صورت اتوماسیون اجرا نمود، ذکر خواهد شد.
- دنبال کردن قیمتهای بازار سهام یا ارزهای دیجیتال
- ارسال یادآور یا همان Notification متنی برای انجام کارهای روزمره
- بهروزرسانی لیست خرید مواد
- تغییر نام دستههای بزرگی از فایلها
- تبدیل فایلهای متنی به صفحات گسترده
- پر کردن فرمهای آنلاین به صورت خودکار
ویژگیها و ابزارهای پایتون
در نتیجه پشتیبانی گسترده جامعه کاربری و ساختار نحوی زبان برنامهنویسی پایتون، یادگیری آن نسبتاً آسان است. برخی از دورههای آنلاین به کاربران برنامهنویسی پایتون را در شش هفته آموزش میدهند. پایتون نیز ماژولها و بستههایی را برای یادگیری فراهم کرده است که قابلیتهایی مانند ساختار نحوی برنامههای آماده و استفاده مجدد از کدها را پشتیبانی میکند. برخی از ویژگیهای پایتون مانند محیط توسعه، ابزارهای پشتیبانی و کتابخانههای متن باز آن را در ادامه توضیح خواهیم داد.
توضیح عکس: ابزارهای پشتیبانی پایتون برای اجرای اسکریپتهای پایتون در محیط دسکتاپ استفاده میشوند.
- محیط توسعه یکپارچه یا به صورت مخفف IDLE، محیط استاندارد توسعه پایتون است. این محیط امکان دسترسی به پایتون را از طریق پنجره پایتون فراهم میکند. کاربران همچنین میتوانند از Python IDLE برای ایجاد یا ویرایش فایلهای منبع موجود پایتون با استفاده از ویرایشگر فایل استفاده کنند.
برخی از ویرایشگرهای متن مرسوم نظیر NotePad را میتوان برای ویرایش دستورات و زبان نحوی پایتون پیش از ورود به محیط IDLE استفاده نمود.
- PythonLauncher یکی از ابزارهای پشتیبانی پایتون است که به توسعهدهندگان اجازه میدهد اسکریپتهای پایتون را در محیط دسکتاپ اجرا کنند. برنامه PythonLauncher را میتوان به عنوان برنامه پیشفرض برای باز کردن فایلهای اسکریپت پایتون با فرمت .py استفاده کرد.
به این ترتیب کافی است با دوبار کلیک کردن روی آیکون این برنامه در محیط دسکتاپ، از طریق پنجره Finder فایل پایتون مورد نظر را انتخاب کرد. PythonLauncher گزینههای زیادی را برای کنترل نحوه راهاندازی اسکریپتهای پایتون توسط کاربران ارائه میدهد.
- Anaconda یک توزیع متن باز معروف برای زبانهای برنامهنویسی پایتون و R است که با بیش از 300 کتابخانه داخلی تهیه شده و به طور ویژه برای پروژههای ML توسعه یافته است. هدف اصلی آن سادهسازی مدیریت و استقرار بستههای کد در محیط برنامهنویسی پایتون میباشد.
مزایای پایتون
پایتون به دلایل زیادی یک زبان برنامهنویسی محبوب است.
- پایتون ساختار نحوی سادهای دارد که از زبان طبیعی انسان تقلید میکند، بنابراین خواندن و درک آن آسانتر است. این باعث میشود پروژههای برنامهنویسی سریعتر و سادهتر توسعه یابند.
- پایتون همه کار است، یعنی میتوان آن را برای اهداف مختلف، از توسعه وب گرفته تا یادگیری ماشینی استفاده کرد.
- پایتون برای مبتدیان بسیار مناسب است، و همین مسئله این زبان را برای کد نویسان سطح ابتدایی محبوب کرده است.
- پایتون یک زبان متن باز است، به این معنی که استفاده و انتشار آن حتی برای مقاصد تجاری رایگان است.
- آرشیو ماژولها و کتابخانههای پایتون بسیار گسترده است. بستههای کد آماده که کاربران شخص ثالث برای گسترش قابلیتهای پایتون ایجاد کردهاند به صورت رایگان در دسترس همگان قرار دارد.
- پایتون دارای یک جامعه بزرگ و فعال است که به مجموعه ماژولها و کتابخانههای پایتون کمک میکند و به عنوان یک منبع مفید برای برنامهنویسان دیگر قابلدسترسی است. جامعه پشتیبانی گسترده به این معنی است که اگر برنامهنویسها با مانعی مواجه شوند، یافتن راهحل آن نسبتاً آسان است زیرا احتمالاً کسی قبلاً با همین مشکل روبرو شده و راهحل آن را منتشر کرده است.
- خوانایی خطوط برنامه ویژگی مهم پایتون است. خطوط کد نوشته شده در پایتون به راحتی قابلخواندن هستند. به عنوان مثال، پایتون به جای نقطهویرگول یا پرانتز، از یک خط فاصله در قالب یک خط کد جدید برای تکمیل یک دستور استفاده میکند.
معایب پایتون
برخی از معایب زبان برنامهنویسی پایتون را میتوان به صورت زیر خلاصه کرد:
- سرعت این زبان برنامهنویسی در مقایسه با زبانهای ++C و C کمتر است. البته این زبان در مقایسه با زبانهای یاد شده یک زبان سطح بالا است (یعنی به زبان انسانها نزدیکتر میباشد) بنابراین سازگاری کمتری با سختافزارها دارد و از این رو سرعت آن هم کمتر است.
- در کاربردهایی که حافظه زیاد مورد نیاز است، پایتون گزینه خوبی نیست. به این دلیل که به خاطر انعطافپذیری بالای این زبان برنامهنویسی و حساسیت به نوع داده، حافظه بیشتری را اشغال میکند.
- از آنجایی که ساختار زبان پایتون دینامیک و پویا است، به تستهای بیشتری نیاز دارد و معمولاً در حین اجرای اولیه برنامه، بروز یک سری خطاها اجتنابناپذیر است.
مثالهایی برای استفاده از پایتون
سازمانهای مختلفی از زبان پایتون برای توسعه برنامههای خود استفاده کردهاند. برخی از شناختهشدهترین این سازمانها شرکتها عبارتاند از:
- موزیلا که با نام فایرفاکس هم شناخته میشود، بالغ بر 230 هزار لینک کد را با زبان پایتون نوشته است.
- گوگل نیز دارای ابزار اختصاصی برای آموزش پایتون است.
- نتفلیکس برای توسعه نرمافزار مانیتورینگ محلی و داده کاوی در فرآیند انتشار برنامههای تلویزیونی خود از زبان برنامهنویسی پایتون استفاده کرده است.
- Reddit کلاً با زبان پایتون نوشته شده است و کدهای منبع آن هم روی GitHub قابلدستیابی است.
جمعبندی
پایتون یک زبان برنامهنویسی محبوب به خصوص در میان علاقهمندان به توسعه وبسایتها و اپلیکیشنها و کاربردهایی مانند پردازش داده است. اما علت محبوبیت پایتون چیست؟ این زبان به دلیل ساختار نحوی سادهای که دارد، برای افراد مبتدی هم قابل استفاده بوده و پیادهسازی آن آسان است.
منابع متعددی برای آموزش این زبان برنامهنویسی وجود دارد که در کنار جامعهی کاربری گسترده، استفاده از آن را برای همه افراد ساده میسازد. حتی افراد عادی و غیر برنامهنویس هم میتوانند بسیاری از کارهای روزمرهی خود را با این زبان بر اساس ساختار اتوماسیون انجام دهند.
بنابراین اگر به عنوان یک فرد تازهکار به دنبال یادگیری یک زبان برنامهنویسی هستید، پایتون یک انتخاب عالی برای شما خواهد بود.
منبع: پایتون چیست و چه کاربردی دارد؟
![]()
جهت مشاهده محتویات و مقالات آموزشی بیشتر به وبسایت ما مراجعه نمائید:
 https://www.m-fozouni.ir/
https://www.m-fozouni.ir/
جهت مشاهده پستهای آموزشی کوتاه در خصوص علم داده به اینستاگرام ما مراجعه نمائید:
elmedade ![]()